BERT
论文阅读——《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
源码链接:google-research/bert: TensorFlow code and pre-trained models for BERT (github.com)
1、模型的输入、输出
模型输入:文本中字词的词向量,文本向量,位置向量。
模型输出:文本融合全文语义信息后的向量表示。
PS:英文词汇可以划分成细粒度的语义单位,例如doing可以划分为do和ing

2、预训练任务
预训练流程如下:
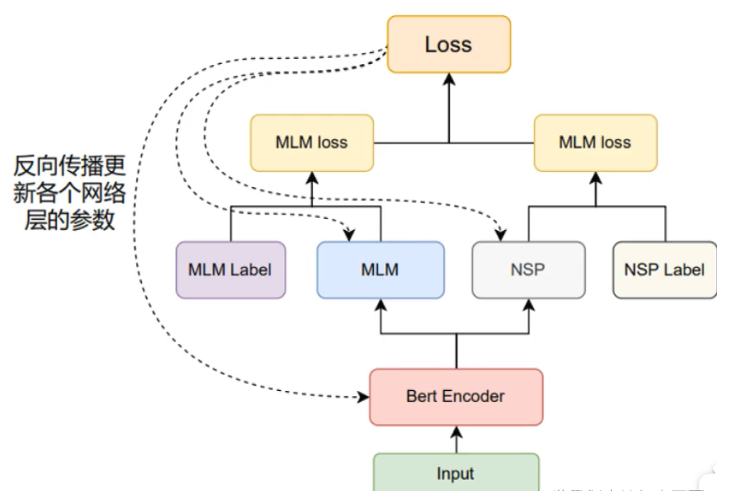
- \(Bert Encoder\):采用默认的12层\(transformer encoder layer\)对输入进行编码。编码后输出的张量形状:\([Batch Size, SeqLens, Emb Dim]\)。
- \(MLM\)模块:掩蔽语言模型,可以理解为完形填空,mask句子中若干词,用周围词去预测遮盖的词。作者会随机mask每一个句子中15%的词,用其上下文来做预测。
80%的时间是采用[mask],my dog is cute → my dog is [MASK]
10%的时间是随机取一个词来代替mask的词,my dog is cute -> my dog is apple
10%的时间保持不变,my dog is cute -> my dog is cute
这样做的目的是因为Transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"cute"。
- \(NSP\)模块:下个句子预测,判断句子B在文章中是否属于句子A的下一句。选择句子对(A,B),B中50%的数据是A的下一条句子,剩余50%的数据是语料库中随机选择的,学习其中的相关性。
3、微调
对于下游不同的NLP任务,模型的输入会进行微调,例如:

- 单文本分类任务
对于文本分类任务,BERT模型在文本前插入一个\([CLS]\)符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类。
- 语句对分类任务
该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,\(BERT\)模型除了添加\([CLS]\)符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个\([SEP]\)符号作分割,并分别对两句话附加两个不同的文本向量以作区分。
4、模型效果

除了架构差异之外,\(BERT\)和\(OpenAI GPT\)都是调优方法,而\(ELMo\)是基于特性的方法。

\(BERT_{LARGE}\)在各项评估指标上的效果要明显好于过往的模型。