Better Few-Shot Relation Extraction with Label Prompt Dropout
《Better Few-Shot Relation Extraction with Label Prompt Dropout》
原文链接:arxiv.org/pdf/2210.13733.pdf
1、概述
本文提出了一种新方法——LPD(Label Prompt Dropout),该方法将文本标签与上下文句子连接后传入Transformer Encoder。用文本标签代替标签提示符,知道Encoder关注自身输出标签感知的关系表示。在训练期间,模型还会随机删除提示符号来使模型学会在使用(不使用)关系描述的情景下进行训练。

2、模型构建
2.1 Training with Label Prompt Dropout
每个输入实例都是由\(:\)将label prompt和上下文文本连接起来,来让Transformer Encoder学习到标签的关系表示。
以一定概率随机剔除label prompt来防止模型依赖prompt而忽略上下文文本。
使用特殊标记来标记上下文文本头尾以及分离token,例如:“[CLS] location of event: [E1] Beijing [/E1] held the [E2] 2022 winter Olympics [/E2] .”并将分离token起始位置的最后一层表示连接起来:\(r=[\mathrm{Encoder}(x)_h;\mathrm{Encoder}(x)_t]\), h表示[E1]的位置,t表示[E2]的位置,r为关系表示。
对于K-way- n -shot学习,对一个类中K个支持实例的关系表示进行平均,以获得类原型。然后计算查询实例与每个类原型之间的点积,作为交叉熵损失中的logit: \[ \begin{gathered} u^{n}={\frac{1}{K}}\sum_{k=1}^{K}r_{k}^{n} \\ {\mathcal L}_{train}=-\sum_{n=1}^{N}\log\frac{\exp(r_{q}^{\mathsf{T}}u^{n})}{\sum_{n^{\prime}=1}^{N}\exp(r_{q}^{\mathsf{T}}u^{n^{\prime}})} \end{gathered} \] \(r_{k}^{n}\)代表n类的k-th支持实例,\(r_{q}\)事 查询实例的关系表示。
2.2 Testing with Prompt Guided Prototypes
LPD在测试中不会dropout任何支持实例的label prompt,而是将二者一起输入。通过找到与查询关系表示最接近的类原型来输出预测:\(\hat{y}_{num}=\arg\max_{n}r_{q}^{\top}u^{n}\)
2.3 Contrastive Pre-training with Label Prompt Dropout
本文遵循MT-BERT框架,对对比预训练中使用的正样本和负样本进行抽样。给定一个知识图\(K\)和两个具有实体对(h1,t1)和(h2,t2)的句子,如果K定义了一个关系R,使得(h1,t1)和(h2,t2)属于R,则两个句子标记为正样本,否则作为负样本。如图2所示:

预训练阶段的每个实例与训练阶段的支持实例进行相同的转换。在每个句子前加上一个标签提示,并在句子中插入特殊的标记。使用对比损失来训练模型:\(\mathcal{L}_{CP}=-\log\frac{\exp(r_Ar_B)}{\exp(r_Ar_B)+\sum_{i=1}^N\exp(r_Ar_B^i)}\)。式中\((r_A, r_B)\)为正对,\((r_A, r_{B}^{i}), 1≤i≤N\)为负对。
使用掩码语言建模目标(LMLM)来维持模型的语言理解能力。所以最终的预训练损失变成:\({\mathcal L}_{pre-train}={\mathcal L}_{CP}+{\mathcal L}_{MLM}\)
3、实验结果
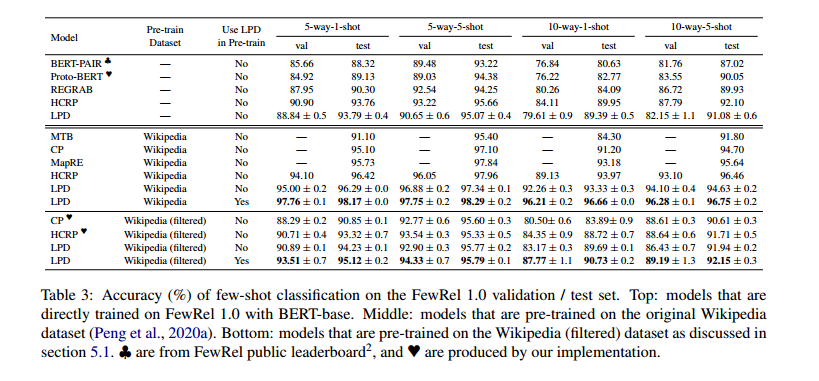

LPD模型在不同类和样本数下的准确率都比以往的模型更高。 ## 4、代码复现
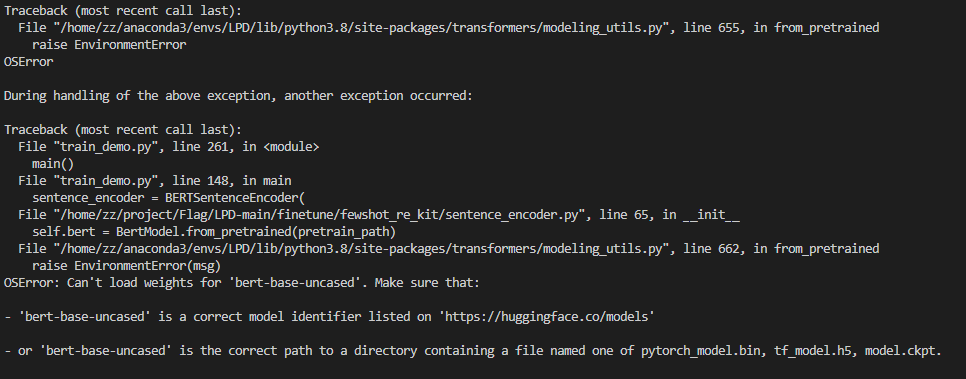
解决方法:手动下载模型并保存在代码目录下

解决方法:修改源代码中的apex-master/apex/amp/utils.py文件
1 | |
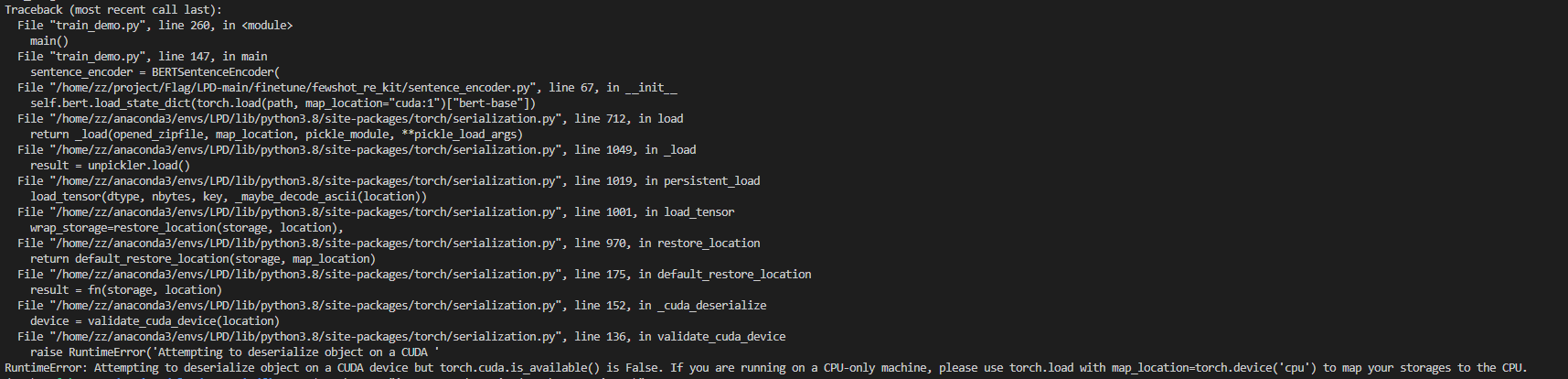
解决方法:首先检查pytorch和CUDA版本是否兼容,其次修改脚本:
1 | |