Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
论文链接:2023.findings-acl.817.pdf (aclanthology.org)
任务定义
给定一个包含N个单词的文档\(\mathcal{D}=\{w_{1},w_{2},...,w_{N}\}\)、预定义事件类型集\(\mathcal{E}\)、对应的角色集\(\mathcal{R_e}\)以及每个事件的触发器\(\mathcal{t}\)。本任务旨在预测文档\(\mathcal{D}\)中每个事件的所有\((r,s)\)对,\(r\in\mathcal{R}_{e}\)是事件\(e\in\mathcal{E}\)的一个参数角色,\(s\in\mathcal{D}\)是\(\mathcal{D}\)中的一个连续文本跨度。
模型构建
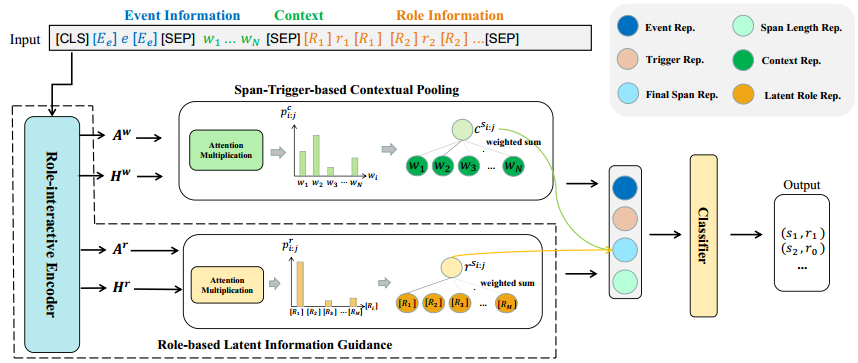
input
本文在embedding的过程中,对于事件信息和角色信息前后加入特殊token来标记特殊信息。
Role-interactive Encoding
对输入内容进行编码后分别得到事件表示\(\mathbf{H}^e\in\mathbb{R}^{l_w\times d}\)、上下文表示\(\mathbf{H}^w\in\mathbb{R}^{l_w\times d}\)以及角色表示\(\mathbf{H}^r\in\mathbb{R}^{l_w\times d}\),\(l_w\)为词块列表的长度,\(l_r\)为角色列表的长度。对于大于512的输入序列,本文用动态窗口对序列进行编码,对于不同窗口的重叠标记embedding进行平均,获得最终表示。本文的编码方式旨在获取语义相关性并适应目标事件和上下文。
Span-Trigger-based Contextual Pooling
获取pre-trained model中的最后一个transformers层的token-level上下文信息的attention heads 矩阵:\(\mathbf{A}^w\in\mathbb{R}^{H\times l_w\times l_w}\),一定范围内中每个候选span的上下文attention可以通过average pooling计算得到:\(\mathbf{A}_{i:j}^C=\frac{1}{H(j-i+1)}\sum_{h=1}^H\sum_{m=i}^j\mathbf{A}_{h,m}^w\).对于span-trigger对\((s_{i:j},t)\),将注意力相乘后归一化得到上下文中线索信息的相关性矩阵: \[ \begin{aligned}\mathbf{p}_{i:j}^c&=softmax(\mathbf{A}_{i:j}^C\cdot\mathbf{A}_t^C),\\\mathbf{c}^{s_{i:j}}&=\mathbf{H}^w\mathbf{p}_{i:j}^c,\end{aligned} \]
Role-based Latent Information Guidance
与上述模块类似,获取pre-trained model 中最后一个transformers层的角色信息的attention head矩阵\(\mathbf{A}^r\in\mathbb{R}^{H\times l_w\times l_w}\),可以计算得到潜在角色信息的相关性矩阵: \[ \begin{gathered} \mathbf{A}_{i:j}^{R}=\frac{1}{H(j-i+1)}\sum_{h=1}^{H}\sum_{m=i}^{j}\mathbf{A}_{h,m}^{r}, \\ \mathbf{p}_{i:j}^{r}=softmax(\mathbf{A}_{i:j}^{R}\cdot\mathbf{A}_{t}^{R}), \\ \mathbf{r}^{s_{i:j}}=\mathbf{H}^{r}\mathbf{p}_{i:j}^{r}, \end{gathered} \] 对于一个候选span,将average pooling、上下文中的线索信息以及潜在角色信息进行融合: \[ \mathbf{s}_{i:j}=tanh(\mathbf{W}_1[\frac{1}{j-i+1}\sum_{k=i}^j\mathbf{h}_k^w;\mathbf{c}^{s_{i:j}};\mathbf{r}^{s_{i:j}}]), \] \(\mathbf{W}_1\in\mathbb{R}^{3d\times d}\)为可学习参数,之后的\(W\)均为可学习参数。
Classification Module
Boundary loss:
由于前面的工作是在span层面提取参数,可能对于边界的限定是模糊的,因此在该模块使用全连接神经网络构造起点和终点来强化span的范围表示:\(\mathbf{H}^{start}=\mathbf{W}^{start}\mathbf{H}^{s},\mathbf{H}^{end}=\mathbf{W}^{end}\mathbf{H}^{s}\),\(H^s\)是输入序列的隐藏表示。在该基础上,将上下文和角色信息与基于span-trigger的上下文pooling相结合,增强开始和结束的表示: \[ \begin{gathered} \mathbf{z}_{i:j}^{start}=\mathbf{H}^{start}\mathbf{p}_{i:j}, \\ \mathbf{z}_{i:j}^{end}=\mathbf{H}^{end}\mathbf{p}_{i:j}, \\ \mathbf{h}_{i:j}^{start}=tanh(\mathbf{W}_{2}[\mathbf{h}_{i}^{start};\mathbf{z}_{i:j}^{start}]), \\ \mathbf{h}_{i:j}^{end}=tanh(\mathbf{W}_{3}[\mathbf{h}_{j}^{end};\mathbf{z}_{i:j}^{end}]), \end{gathered} \] \(h_i\)表示\(H\)的第i个向量。
通过上述处理后可以得到span的最终表示:\(\widetilde{\mathbf{s}}_{i:j}=\mathbf{W}^{s}[\mathbf{h}_{i:j}^{start};\mathbf{s}_{i:j};\mathbf{h}_{i:j}^{end}]\)
boundary loss可以表示为: \[ \begin{aligned}\mathcal{L}_b&=-\sum_{i=1}^{|\mathcal{D}|}[y_i^s\log P_i^s+(1-y_i^s)\log(1-P_i^s)+y_i^e\log P_i^e+(1-y_i^e)\log(1-P_i^e)]\end{aligned} \] \(y_i^{s}、y_i^{e}\)表示真实的labels,\(P_i^{s}=sigmoid(\mathbf{W}_{4}\mathbf{h}_{i}^{start})、P_i^{e}=sigmoid(\mathbf{W}_{5}\mathbf{h}_{i}^{end})\)代表单词\(w_i\)被预测为真实参数span的第一个、最后一个词的概率。
Classification Loss:
本文将事件e中的候选span\(\widetilde{\mathbf{s}}_{i:j}\)、trigger表示\(h_t\)、二者差的绝对值、两个矩阵对应元素相乘得到的矩阵、事件类型的embedding以及span长度的embedding concatenate起来,通过一个前向传播网络,得到预测值: \[ \begin{aligned}\mathbf{I}_{i:j}&=[\widetilde{\mathbf{s}}_{i:j};\mathbf{h}_t;|\mathbf{h}_t-\widetilde{\mathbf{s}}_{i:j}|;\mathbf{h}_t\odot\widetilde{\mathbf{s}}_{i:j};\mathbf{H}^e;\mathbf{E}_{len}],\\\\&P(r_{i:j})=\mathrm{FFN}(\mathbf{I}_{i:j})\end{aligned} \] 由于大多数候选参数是负样本以及不符合事件类型的角色分布,本文采用focal loss来让模型更加关注有用的正样本: \[ \begin{aligned}\mathcal{L}_{c}&=-\sum_{i=1}^{|\mathcal{D}|}\sum_{j=1}^{|\mathcal{D}|}\alpha[1-P(r_{i:j}=y_{i:j})]^{\gamma}\cdot\log P(r_{i:j}=y_{i:j})\end{aligned} \] \(α、γ\)都是超参数
最后总loss:\(\mathcal{L}=\mathcal{L}_{c}+\lambda\mathcal{L}_{b}.\)