Transformer
Transformer学习笔记
1、架构
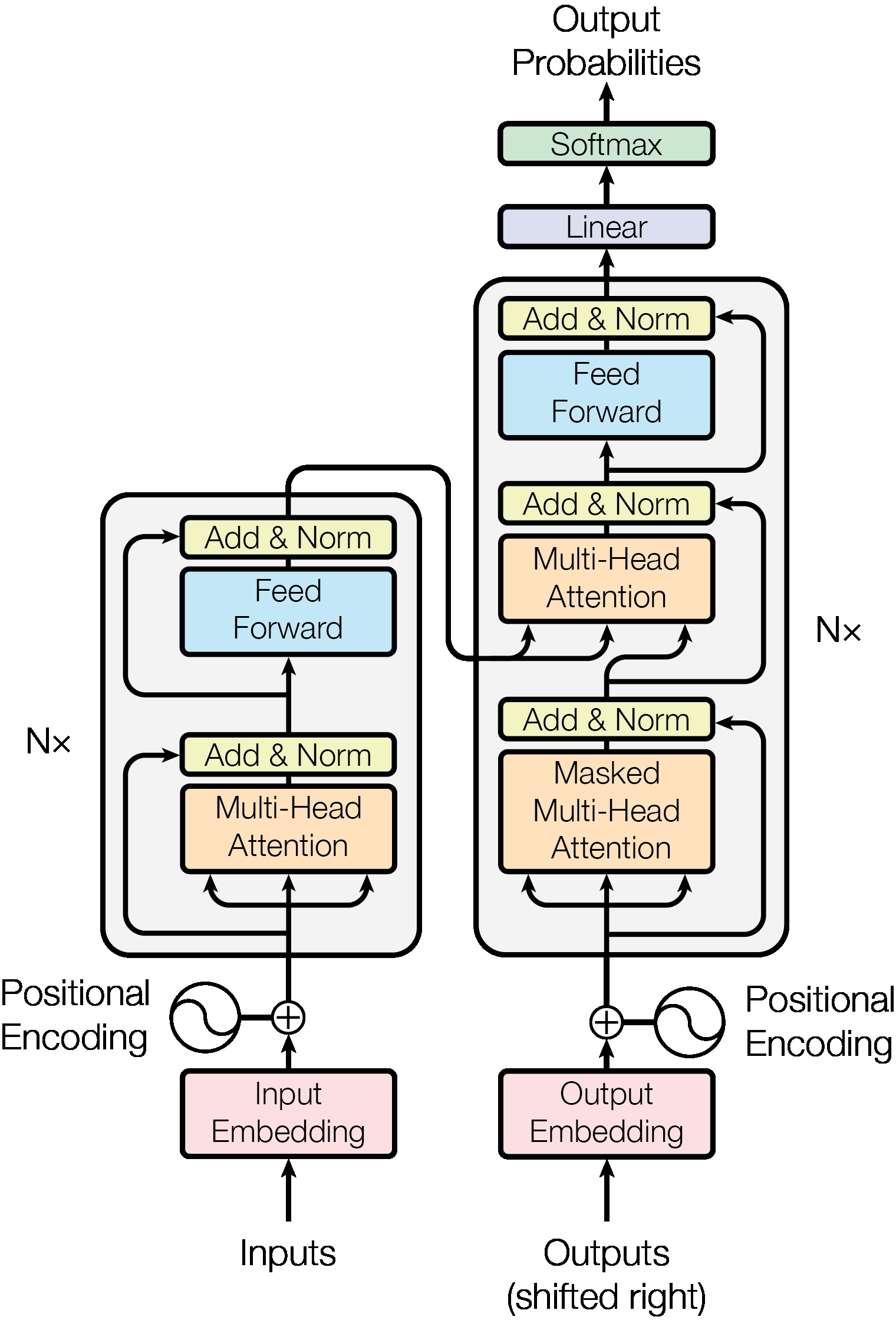
上图是\(Transformer\)的详细架构,可以从中抽象出基础模块进行理解:
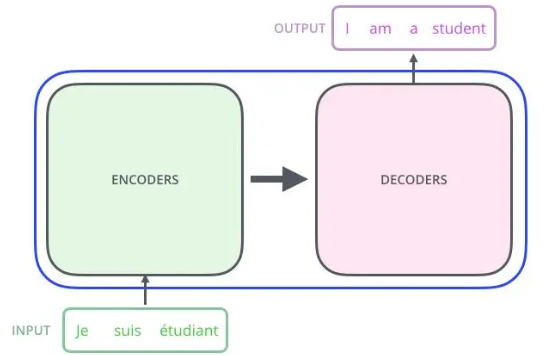
以翻译任务为例,可以将\(Transform\)理解成一个黑盒,输入模型一句话,输出能够得到一个翻译结果。Transform是一个\(Seq2Seq\)模型(\(Encoder-Decoder\) 框架的模型),$Encoder和Decoder $默认是有6层:
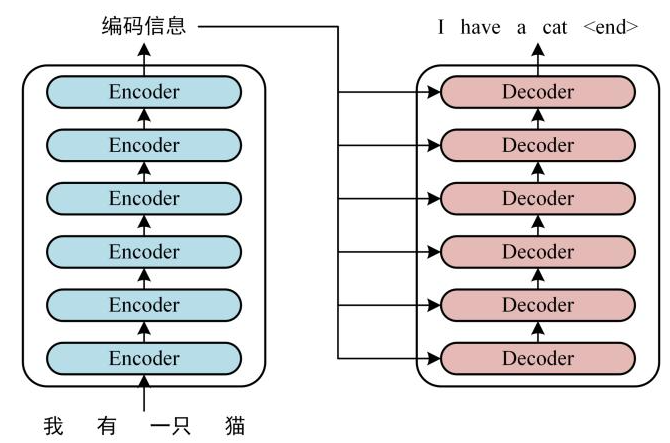
这里\(Encoders\)的输出会和每一层的\(Decoder\)进行结合,原因是Encoder向每层的Decoder输入KV,Decoder 产生的Q 从Encoder的KV中查询信息。
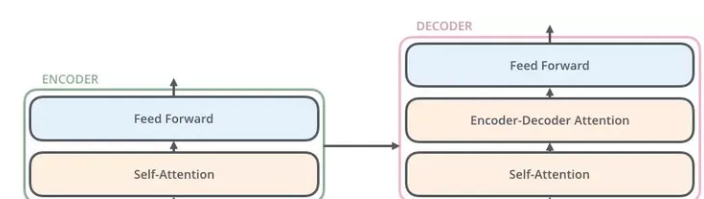
2、Encoder
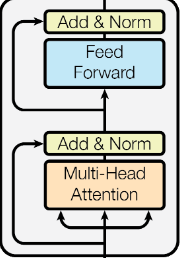
从图5中可以看到,\(Encoder\)包含两个子层:
- 第一个是Multi-Head self-Attention,用于计算输入的\(self-attention\);
残差模块表示: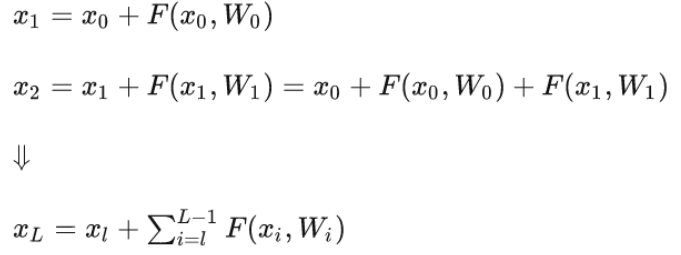
残差结构的作用:避免出现梯度消失的情况,由图5所示,网络在反向传播时,错误信号可以不经过任何中间权重矩阵变换直接传播到低层,一定程度上可以缓解梯度消失问题。
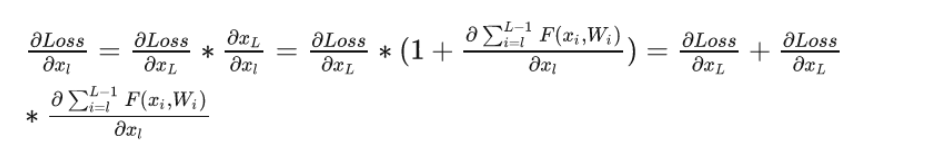
Layer Norm作用:保证数据特征分布的稳定性,并且可以加速模型的收敛。
为什么Transformer用Layer Norm
Layer Norm主要解决的是内部变量转移(Internal Covariate Shift)的问题,在传统深度神经网络中,通常采用批归一化(Batch Normalization)来解决这个问题,但是在Transformer中,每个位置的输入都是高维变量,Batch Norm会破坏向量的位置信息。Layer Norm对每个样本单独计算均值和方差,不会破坏向量的位置信息。
- 第二个是简单的前馈神经网络层。每个层的输出都会通过残差网络:\(LayerNorm (x + Sub_layer(x))\)。
Feed Forward作用:
3、Decoder
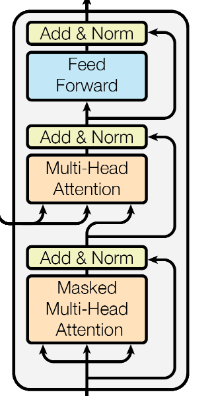
Decoder包含三个层:两个Multi-Head self-Attention 层和一个Feed Forward层
第一个 Multi-Head Attention
该层采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。
- 输入Decoder矩阵和对应的Mask矩阵
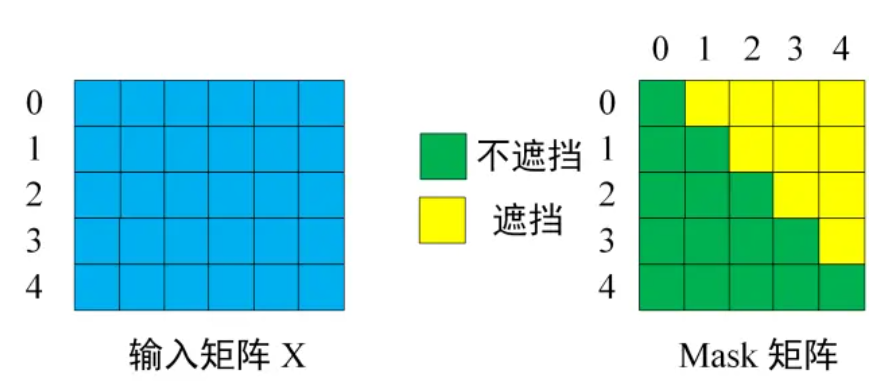
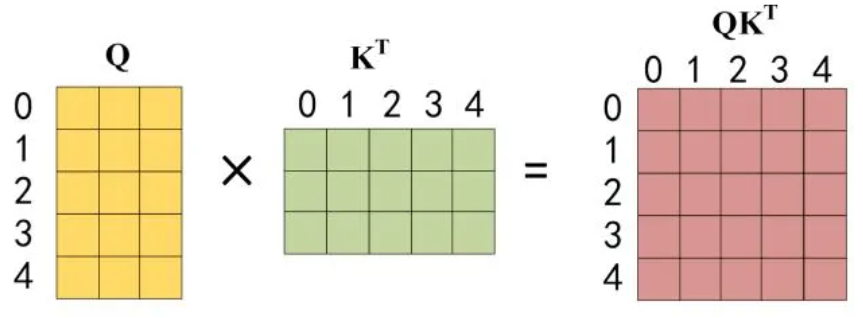
- 与上述self-attention一样
- 在得到最终\(QK^T\)之后需要进行\(Softmax\),在\(Softmax\)之前需要用Mask矩阵遮挡每一个单词之后的信息
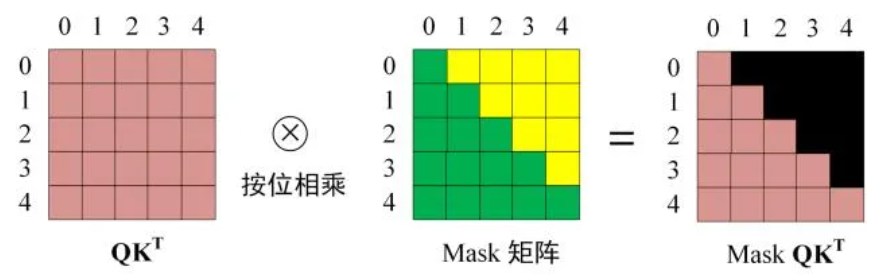
- 后续步骤和Encoder的self-attention模块一致
第二个 Multi-Head Attention
第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息。
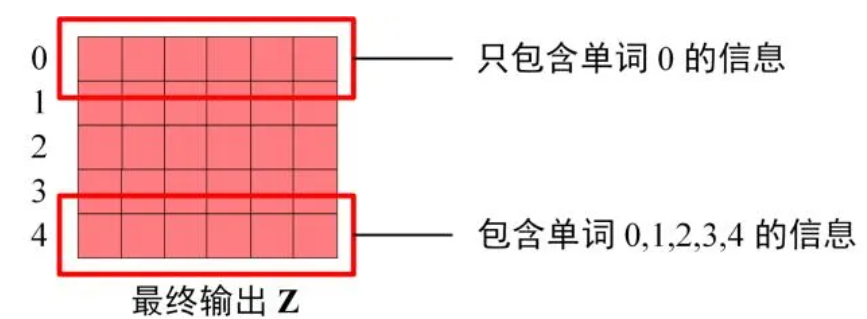
Softmax 预测输出单词
最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出 Z,因为 Mask 的存在,使得单词 0 的输出 Z0 只包含单词 0 的信息,如下: