GPT系列模型
GPT系列模型
1、GPT1
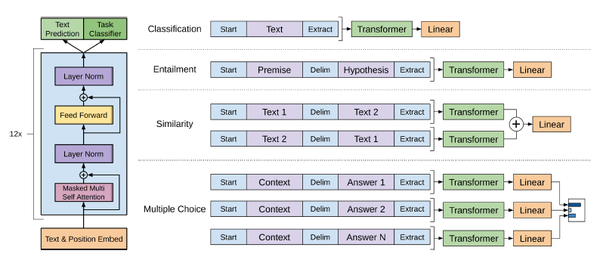
训练过程
- pre-train:利用大量无标注的语料进行预训练
- SFT(Supervised Fine-Tuning):利用NLP任务的数据进行微调
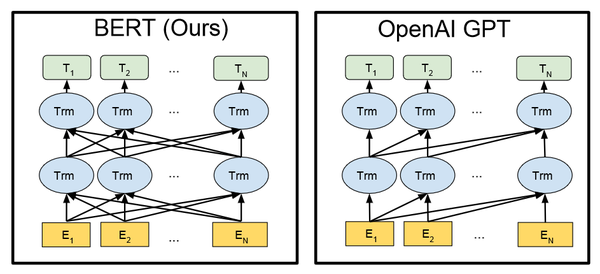
GPT1是一个decoder—only模型,模型的目标是让下一个词预测的概率最大
2、GPT2/3
与GPT1结构没有变化,但是训练数据集和模型的参数量更大(模型的层数更多,模型更复杂1)
3、GPT3.5
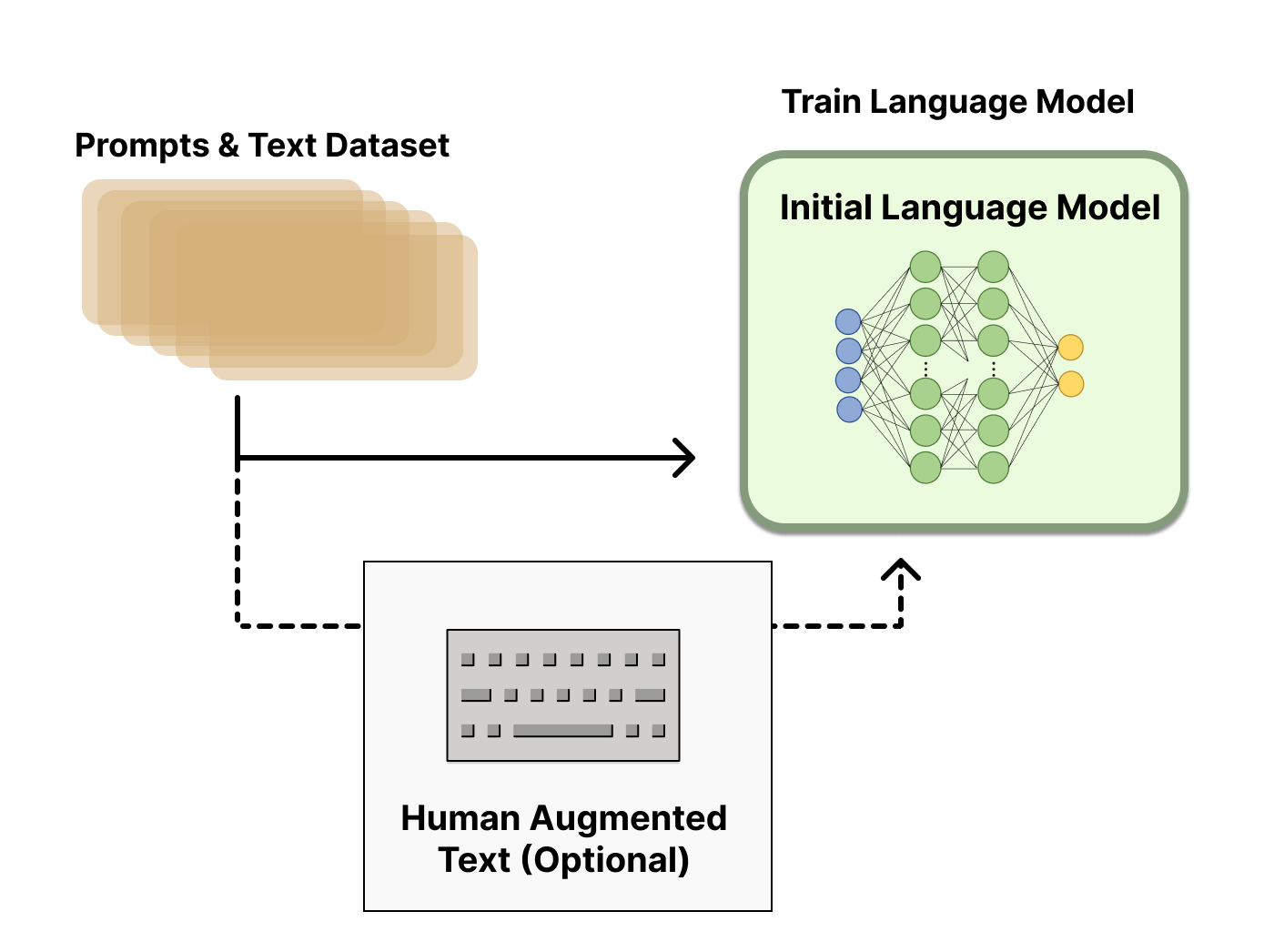
训练过程
pre-train:利用大量无标注的语料进行预训练
SFT(Supervised Fine-Tuning):利用NLP任务的数据进行微调
RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)
- 得到一个SFT后语言模型(LM)
- 训练一个奖励模型(Reward Model,RM)
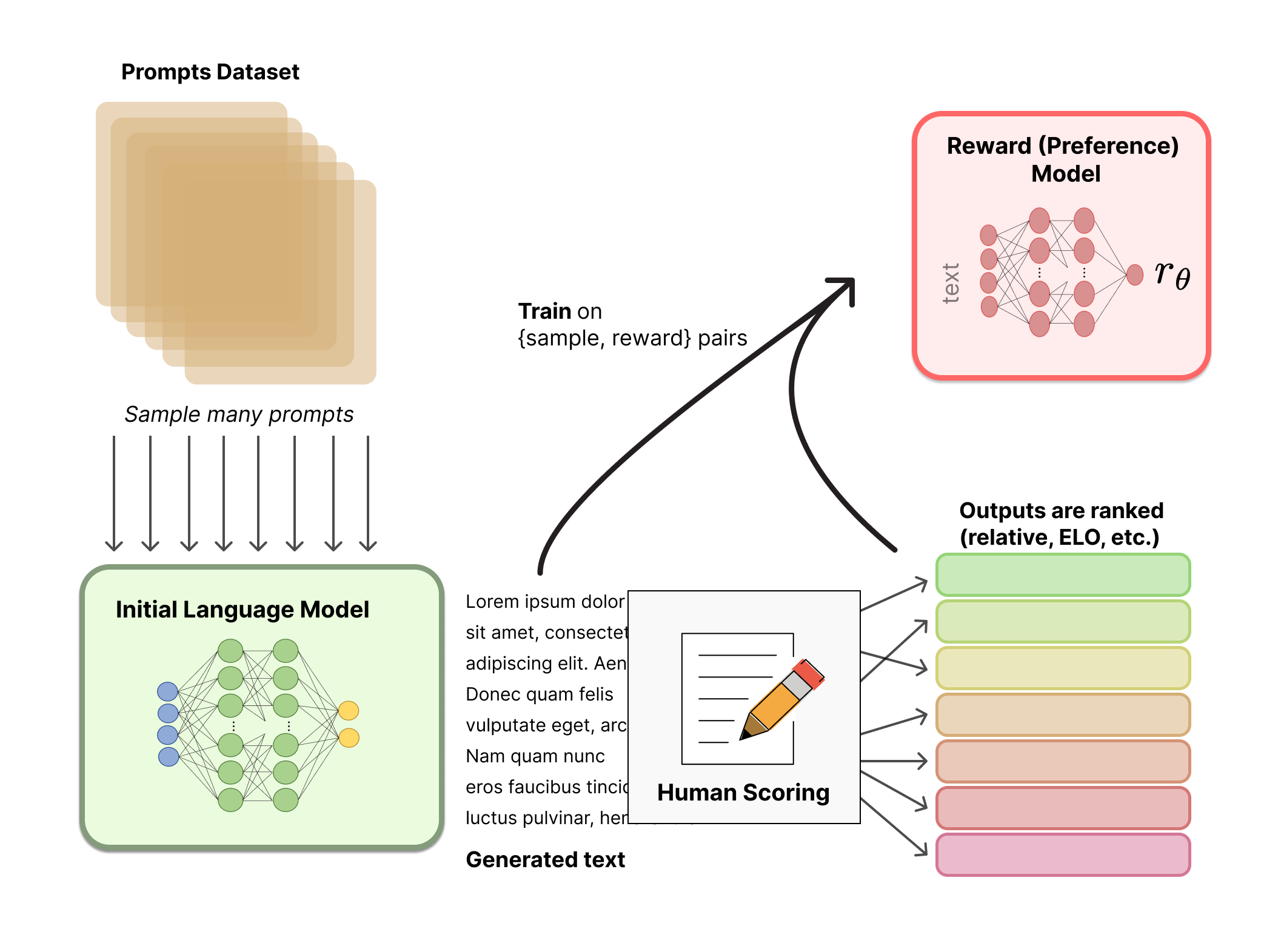
奖励模型训练过程是接受一系列文本并返回一个标量奖励,数值上对应人的偏好。关于模型选择方面,RM可以是另一个经过微调的LM,也可以是根据偏好数据从头开始训练的LM。RM通常比LM的规模小一些。
RM的输入是
对于RM来说,模型目标是对一个句子进行打分,通常来说每个句子对应一个分值,但是RM对长度为
- 用强化学习方式微调(LM)
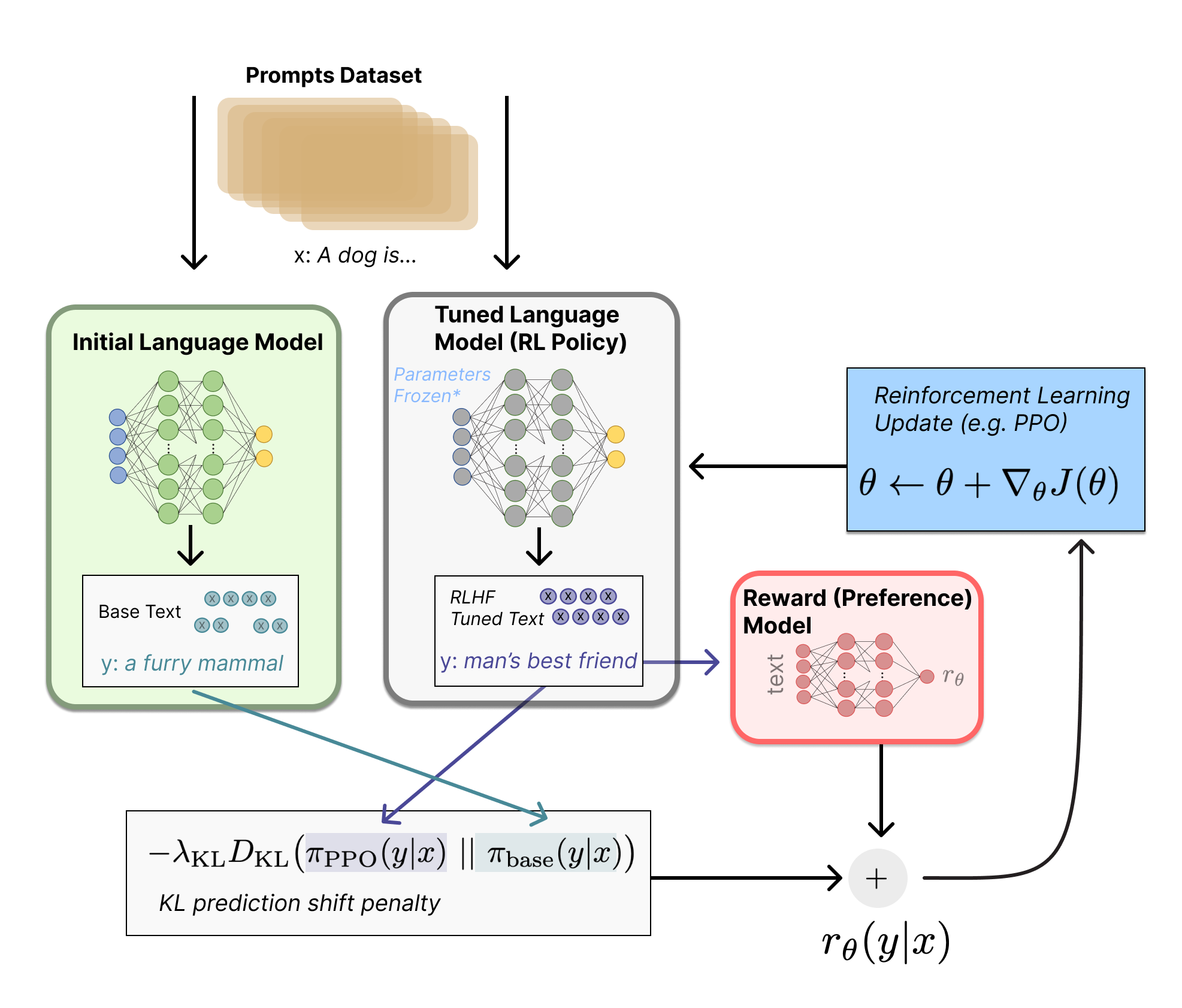
此处LM模型是进行推理。LM的训练模型和推理模式的区别:训练模式是用teacher force的方式(在每一轮预测时,不使用上一轮预测的输出,而强制使用正确的单词,过这样的方法可以有效的避免因中间预测错误而对后续序列的预测,从而加快训练速度),将整句话输入到模型中,并通过mask机制,在保证不泄漏未来的单词情况下预测下一个单词。推理模式是真正的自回归,预测出下一个单词之后,当作下一步输入再预测下下个单词。
可以将微调任务表述为RL问题,目前可行的方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 、直接偏好优化算法(Direct Preference Optimization,DPO)微调初始 LM 的部分或全部参数。
首先,该 策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
PPO算法
PPO 算法确定的奖励函数具体计算如下:
首先将提示 x +预训练的输出answer输入当前微调的推理模式下的
LM,将得到的输出传递给 RM 得到一个标量的奖励
PPO训练时候的奖励值综合考虑KL散度和reward模型的输出,只考虑answer部分的KL散度,将reward model的输出加到KL散度L维度的最后一个位置上,得到最终的奖励值。
训练过程中的目标函数是更新PPO更新公式里边的advantage。Advantage 函数计算在状态下执行该操作与状态的平均值相比有多好。它从状态操作对中减去状态的平均值:

换句话说,此函数计算如果我们在该状态下执行此操作时获得的额外奖励,与我们在该状态下获得的平均奖励相比:
- 如果
- 如果
求解Advantage函数可以转换为求两个值函数,对于求接值函数我们又可以转换为求解TD Error:

DPO算法

相比于PPO算法的强化学习过程,DPO跳过了训练RM的步骤,直接用偏好数据优化语言模型。算法的核心观点是利用从奖励函数到最优策略的解析映射,将对奖励函数的损失转化为对策略的损失。
RL问题中的目标是最大化奖励函数:
GPT4
核心技术
涌现能力(Emergent Abilities)
该能力是指模型具有从原始训练数据中自动学习并发现新的、更高层次的特征和模式的能力。当模型的参数量到达一定量级时,模型的性能有明显的提升。
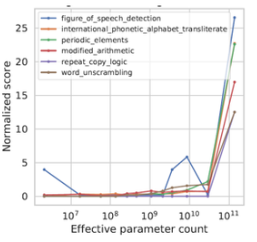
缩放定律(Scaling Laws)
该定律是指模型性能(如测试集上的预测精度)随着模型参数的数量以及训练过程中使用的数据量和计算量的对数线性增长。
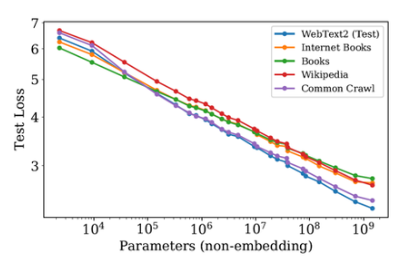
优点:
- 提前预测最终模型效果,知道每次训练的大概能到什么程度,要是不及预期可以根据预算再进行调整
- 在小尺寸模型上做置信的实验,进行数据、算法策略验证,降低实验的时间、资源成本
- 在真正的大规模预训练中,随时监测模型效果是否符合预期
思维链(Chain of Thought)

思维链的方法将一个多步骤的问题(例如图表推理)分解为可以单独解决的中间步骤。在解决多步骤推理问题时,模型生成的思维链会模仿人类思维过程。这意味着额外的计算资源被分配给需要更多推理步骤的问题,可以进一步增强GPT-4的表达和推理能力。
一般认为模型的思维推理能力与模型参数大小有正相关趋势,当参数量突破一个临界规模,模型才能通过思维链提示的训练获得相应的能力。
提示工程
GPT3/4 的提示范式可以归纳为:“预训练+提示+预测”(Pre-train+Prompt+Predict)。在这一范式中,各种下游任务被调整为类似预训练任务的形式。通过选取合适的提示,使用者可以控制模型预测输出,从而一个完全预训练模型可以被用来解决多样的下游任务。
幻觉检测
大模型的幻觉(Hallucination)是指:模型生成的输出包含一些与输入不符合的信息,这些信息可能是错误的、无关的或者荒谬的。
大模型的幻觉大体上包含以下几类:
- 含义相关性的幻觉(Semantic Relatedness):模型生成的输出可能包含与输入语境无关或不相关的单词或短语,这些单词或短语通常是通过模型之前接触过的文本来学习的。
- 语义扩张(Semantic Expansion)的幻觉:模型生成的输出可能包含与输入语境相关但是过于具体或者过于抽象的内容,这些内容也可能是通过模型之前接触过的文本来学习的。
- 结构错误的幻觉(Structural Errors):模型生成的输出可能不符合正确的语言表达或句子结构,这些错误可能是由于模型在生成时遗漏了某些信息,或者将不相关的信息结合在一起导致的。