LLM量化
LLM量化(未完待续)
INT8
1、动机和原理
模型的大小由参数量和数据精度决定,一些常见的精度有:
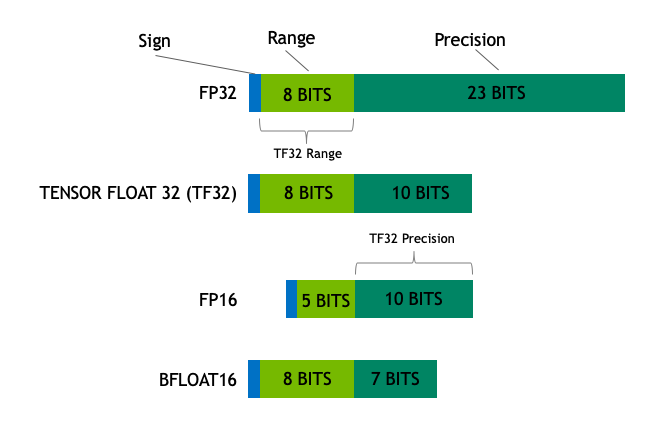
- Float32(FP32):标准的IEEE32 位浮点表示,指数 8 位,尾数 23 位,符号 1 位,可以表示大范围的浮点数。大部分硬件都支持 FP32 运算指令。
- Float16(FP16):指数 5 位,尾数 10 位,符号 1 位。FP16 数字的数值范围远低于 FP32,存在上溢 (当用于表示非常大的数时) 和下溢 (当用于表示非常小的数时) 的风险,通过缩放损失 (loss scaling) 来缓解这个问题。
- Bfloat32(BF16):指数 8 位 (与 FP32 相同),尾数 7 位,符号 1 位。这意味着 BF16 可以保留与 FP32 相同的动态范围。但是相对于 FP16,损失了 3 位精度。因此,在使用 BF16 精度时,大数值绝对没有问题,但是精度会比 FP16 差。
- TensorFloat-32(TF32):使用19位表示,结合了 BF16 的范围和 FP16 的精度,是计算数据类型而不是存储数据类型。目前使用范围较小。
在训练时,为保证精度,主权重始终为 FP32。而在推理时,FP16 权重通常能提供与 FP32 相似的精度,这意味着在推理时使用 FP16 权重,仅需一半 GPU 显存就能获得相同的结果。
在上述基础上,我们可以通过量化技术进一步的减少模型训练时所需的显存消耗。最常见的就是INT8量化。
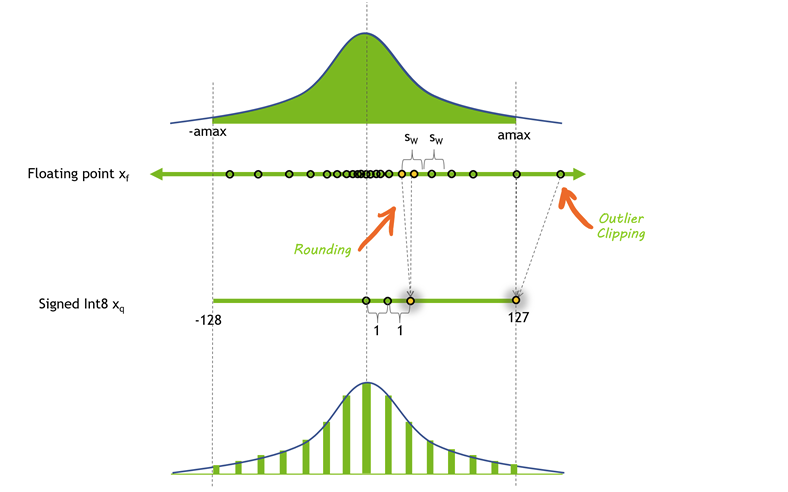
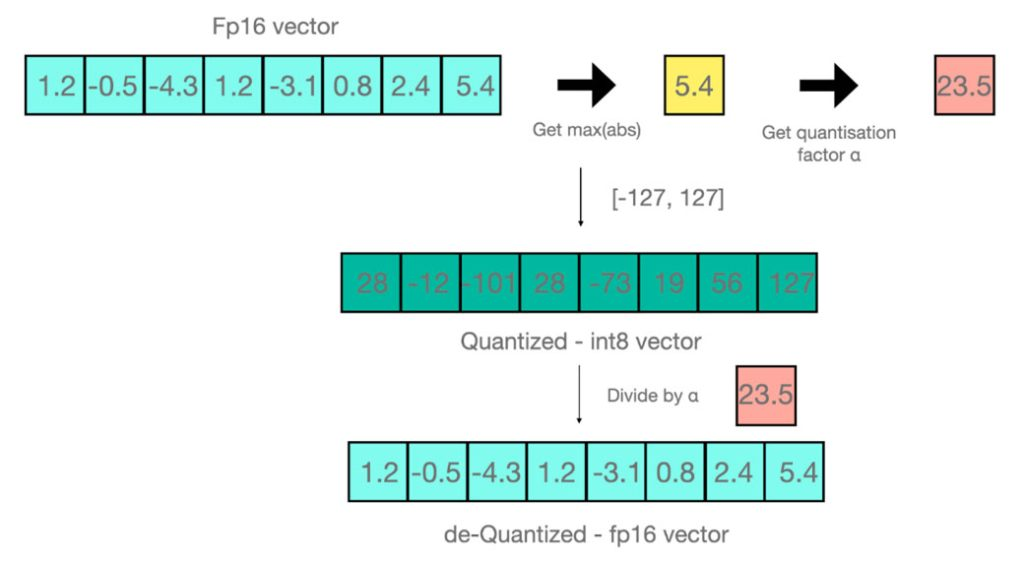
简单来说, INT8 量化即将浮点数\(x_f\)通过缩放因子\(scale\)映射到范围在[-128,127]内的8bit表示\(x_q\),即: \[ x_q=\text{Clip}(\text{Round}(x_f*\text{scale })) \] 其中 Round 表示四舍五入的整数,Clip 表示将离群值(Outlier) 截断到 [-128, 127] 范围内。对于 scale 值,通常按如下方式计算得到: \[ \begin{aligned}&amax=\max\left(abs\left(x_{f}\right)\right)\\&\text{scale}=127/amax\end{aligned} \] 下面是通过该方式实现的量化-反量化的例子:
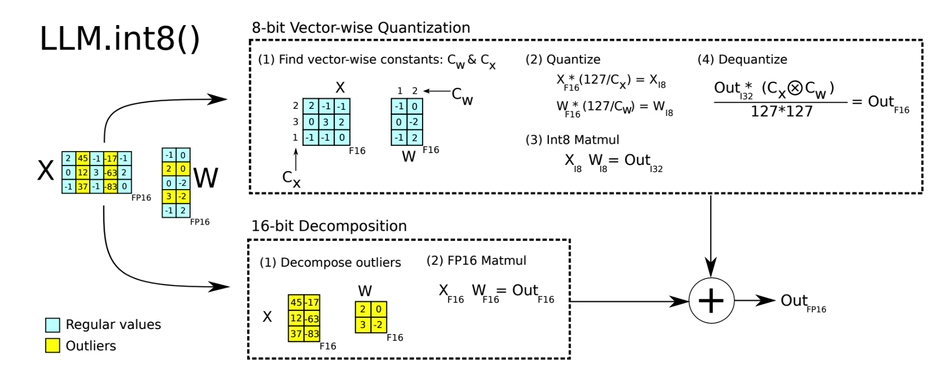
当进行矩阵乘法时,可以通过组合各种技巧,例如逐行或逐向量量化,来获取更精确的结果。
2、int8 量化的精度和性能
在单个向量量化的过程中也存在一定问题,对于一个向量A:
1 | |
注意到向量A中有离群值(Emergent Features)-67.0,如果去掉该值对向量A做量化和反量化,处理后的结果是:
1 | |
出现的误差只有-0.29 -> -0.28。但是如果我们在保留-67.0的情况下对该向量做量化和反量化,处理后的结果是:
1 | |
可见大部分信息在处理后都丢失了。Emergent Features的分布是有规律的。对于一个参数量为6.7亿的transformer模型来说,每个句子的表示中会有150000个Emergent Features,但这些Emergent Features只分布在6个维度中(为什么有这样的规律本人还没了解过)。基于此,可以采用混合精度分解的量化方法:将包含了Emergent Features的几个维度从矩阵中分离出来,对其做高精度的矩阵乘法;其余部分进行量化。如下图所示: